Parsing context-free grammars with Python
A walkthrough of parsing context-free grammars using Lark package.
Context-free grammars are one of the core concepts in formal language theory with a plethora of applications in computer science. In particular, arithmetic expressions in programming languages are usually generated by such grammars. Another prime example of a language admitting context-free grammar is JSON (as defined in RFC 7159). It turns out that context-free grammars can also come in handy in some areas of other sciences. For instance, the syntax of the Crystallographic Information File format can be defined using a context-free grammar (see here).
There exist several algorithms for parsing context-free grammars, such as the Earley parser or CYK algorithm, with implementations available in multiple programming languages. In today’s post I will focus on the usage of one such implementation available in Lark package. In particular we will see how to:
- define your grammar in Lark’s notation,
- create a parse tree,
- transform this tree into a meaningful structure that can be used in your program.
To this end, we will use a toy model - our own simple language based on INI file syntax - and use Lark for parsing files in that language.
All of the code examples in this post use Python 3 (tested on Python 3.7.1) but should work also on Python 2.7, possibly after minor modifications. To run them you will also need to install lark-parser (i.e. by running pip install lark-parser).
Context-free grammars
Let’s first recall what a context-free grammar is. I will skip the formal definition and instead try to build an intuition for this concept. Suppose we want to describe some language, here’s what we need:
- a set of symbols that can appear in the sentences. We will call such symbols terminals.
- a set of symbols, disjoint from terminals, that defines more complex structures (it will hopefully become clear what we mean later on). We will call this set nonterminals.
- a set of rules defining how nonterminals can be expanded. This set will be called productions.
- a starting symbol representing a valid sentence.
We will also require that the sets of terminal symbols, nonterminal symbols and productions are finite. As an example, suppose we want to describe all possible arithmetic expressions involving natural numbers (excluding 0). Obviously, the set of nonterminal symbols will consist of nonzero digits and operators +,-,*,/. Nonterminal symbols are:
- number: a symbol representing a natural number,
- expression: a symbol representing a whole expression. This will also be a start symbol.
What about productions?
- number can be any non-empty string consisting of an arbitrary number of digits. If we would like to go formal we should define a number as being either a single digit or a digit followed by another number.
- expression can be either:
- a single number
- an expression followed by one of the arithmetic operators and then followed by another expression.
One can write our grammar symbolically in the following way::
expression -> number
expression -> expression "+" expression
expression -> expression "-" expression
expression -> expression "*" expression
expression -> expression "/" expression
number -> digit
number -> number digit
it is customary to list all alternatives for the given nonterminal symbol separated by the pipe (“|”) rather than listing them as separate rules. Our grammar becomes then (line breaks included for readability):
expression -> number |
expression "+" expression |
expression "-" expression |
expression "*" expression |
expression "/" expression
number -> digit | digit number
Now, what makes this grammar context-free? Suppose we want to generate some sentence. You begin with start symbol expression and replace it using any production rule. Now you have some sentence containing mixture of nonterminal and terminal symbols. You pick any nonterminal and replace it just like you did with first expression and so on, until you finally reach a state in which only terminal symbols appear. For instance you could generate valid sentence like this:
expression
expression * expression
number * expression
number * expression + expression
number * number + number
2 * number + number
2 * 3 + number
2 * 3 + 4 number
2 * 3 + 47
Note that in the above the only thing we did is picking a nonterminal symbol and replacing it, without regarding any neighboring symbols (its context). This process can be described as a tree, rooted at expression with leaves being terminal characters, where direct descendants of any non-leaf node follow from an application of some production.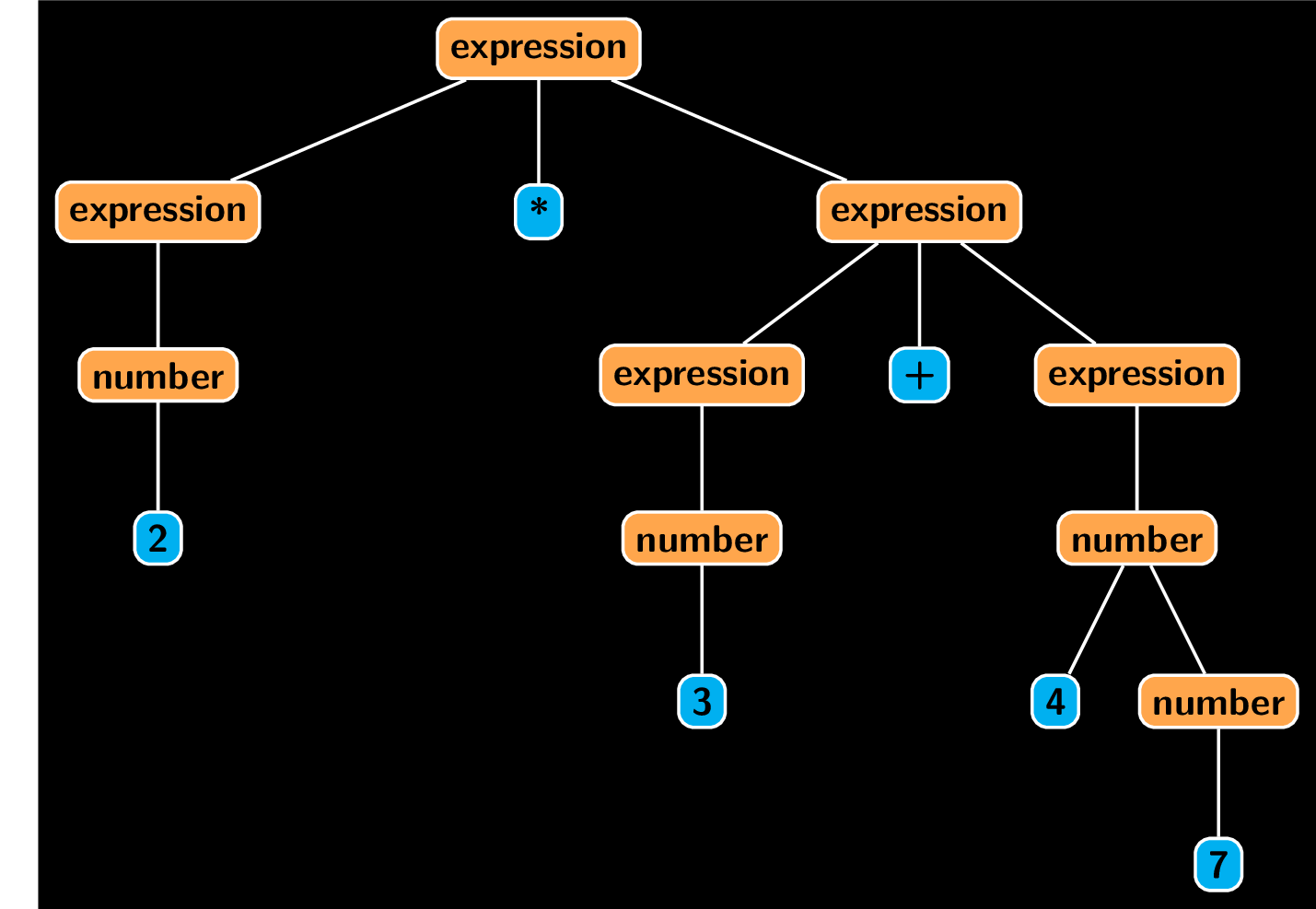
Such a tree, showing a possible derivation of a sentence is called its parse tree. Note that a single sentence can admit multiple parse trees. if such sentence exists, we call the given grammar ambiguous. To illustrate, here is another parse for the same sentence.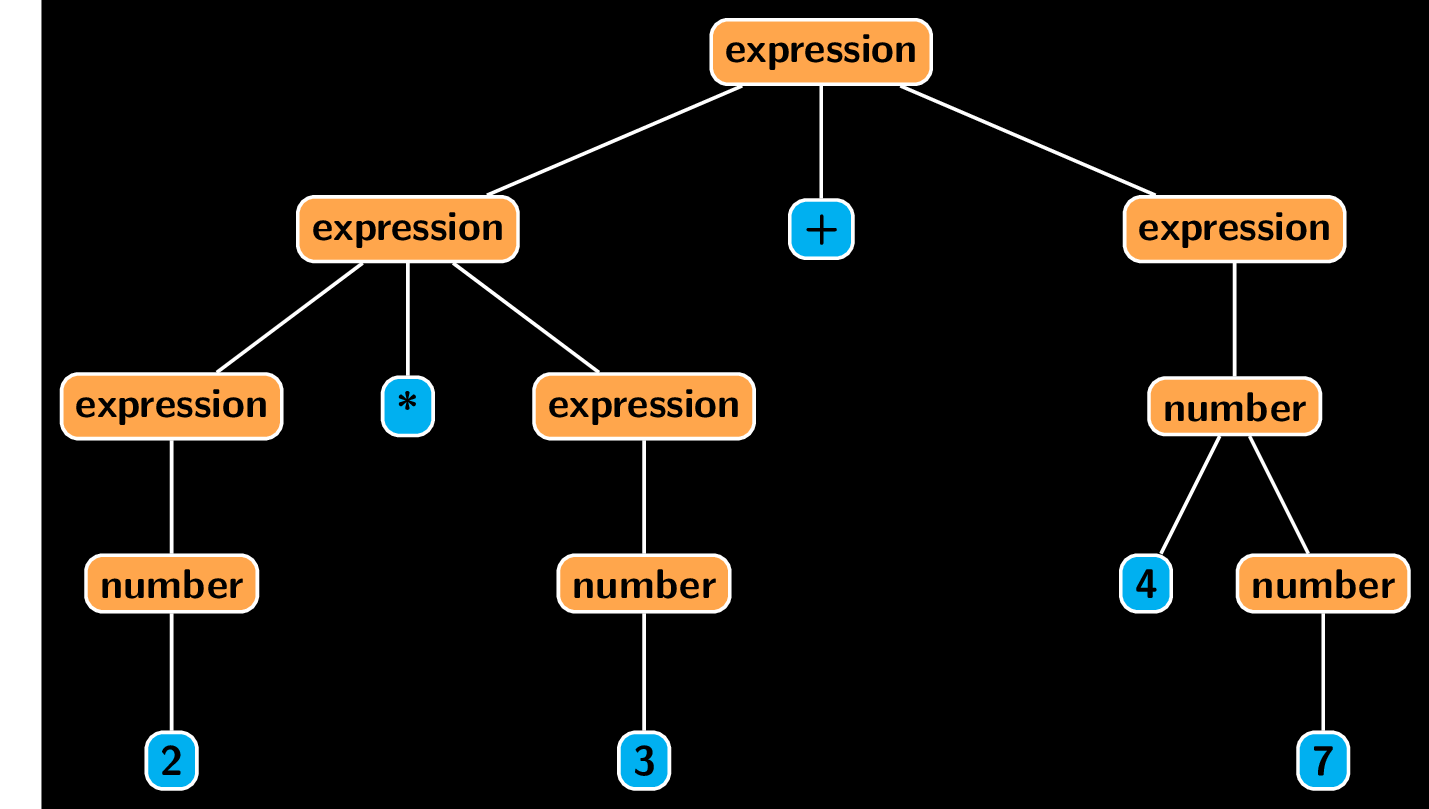
As an example of a grammar that is not context-free (i.e. is context-sensitive), let’s consider language consisting of all the strings of the form $\mbox{a}^n\mbox{b}^n\mbox{c}^n$, that is language consisting of all the words starting with some number of letters “a” followed by the same number of letters “b” followed by the same number of letters “c”. Examples of such words are “abc”, “aabbcc” and so on. This language could be described with the following productions (source: wikipedia).
S -> "a" B C
S -> "a" S B C
C B -> C Z
C Z -> W Z
W Z -> W C
W C -> B C
"a" B -> "a" b
"b" B -> "b" b
"b" C -> "b" C
"c" C -> "c" C
Let’s generate some sentence using this grammar. We start with S and replace it by aBC. What now? We can’t look at a single nonterminal and choose a production to use. It is only when we take into account that B is preceded by “a” that we may use one of the productions to further obtain abC. Then again, we can’t replace C unless we take into account that it is preceded by “b”. We see that for generating sentences using this grammar we can’t look at the nonterminals in isolation but also need context, some knowledge of the given symbol’s surroundings.
The distinction between context-free and context-sensitive grammars is crucial when it comes to parsing as the former are much easier to handle.
Our toy model
Before we see how to parse context-free grammars with Python, let’s first describe our language. As an example, we will parse config files with a syntax similar to this of INI files. Specifically, we would like our files to look something like this
[connection]
host=0.0.0.0
port=8080
[auth]
user=dexter
In other words, our files will consist of sections containing key-value pairs. More specifically:
- Every section should start with a section name enclosed in square brackets. As an additional restriction, we will require that section names start with a letter and contain only letters, digits, and underscores.
- Each section should contain key-value pairs, one pair per line, with key separated from the value with a single “=” sign. We will assume that values are arbitrary strings that don’t contain a newline, “=” sign or spaces. Keys should follow the same restrictions as section_header.
- Our config files should be robust with respect to handling trailing spaces and empty lines. In other words, it should be possible to include blank lines or an arbitrary number of spaces after each line.
- A file following our language should end in a newline character.
Writing grammar for our toy model in Lark
Lark uses specific syntax, similar to EBNF. Its best to see how it works on an example. Grammar for our toy model could look as follows:
start : _EOL* section*
section : section_header entry+
section_header : "[" NAME "]" _EOL
entry : key "=" value _EOL
key: NAME
value : /[^= \n]+/
NAME : LETTER (LETTER | "_" | DIGIT)*
_EOL : " "* ( NEWLINE | /\f/)
%import common.NEWLINE
%import common.LETTER
%import common.DIGIT
Lark distinguishes terminal and nonterminal symbols by their casing. Uppercase names denote terminals and lower case names denote nonterminals. As you see some names start with an underscore, we will get to that later. Note that there are productions defined also for terminal symbols which is not what you would expect from a formal grammar. Everything is fine though, in Lark’s terminology terminals are symbols that appear only as leaves in the parse tree.
Let’s break down productions used in our grammar:
- start: tells us our file will contain an arbitrary number of sections (possibly after some newlines). In particular, we don’t require any section to be present and therefore, an empty file is also valid.
- section: section should consist of a section_header followed by one or more entries.
- section_header: section header is a NAME enclosed in square brackets.
- entry: each entry in a section should be a key followed by “=” followed by a value. An entry ends with an arbitrary non-zero number of _EOL terminals.
- value: values should contain a single terminal NAME.
- key: keys are arbitrary strings not containing newlines, spaces and “=” sign.
There are also several named terminals:
- NAME: consists of a letter followed by an arbitrary number of letters, digits, and underscores.
- _EOL: defined as an arbitrary number of spaces followed by the end of the line.
We also import three predefined terminal symbols: LETTER, DIGIT and NEWLINE with an obvious meaning.
Terminals starting with _ are treated specially, they won’t be included in the parse tree. Moreover, any unnamed terminals present in production for nonterminal symbol will also be stripped. Therefore, our parsed tree will never contain section header enclosed in brackets but rather the enclosed section name.
Now that we have our grammar defined, let’s create a parser.
Creating a parser and obtaining parse tree
This and below sections assume that you saved your grammar as cifgrammar.lark.
Creating parser for our grammar is pretty simple. We just need to create an instance of Lark class and pass it a grammar we want to use. Once our parser is created we may use its parse method to obtain a parse tree of a given sentence. For instance, this is how you could parse a simple config file presented earlier in this post and display its nicely formatted parse tree.
import lark
with open('cfggrammar.lark') as grammar_file:
grammar = grammar_file.read()
cfg = """
[connection]
host=0.0.0.0
port=8080
[auth]
user=dexter
"""
parser = lark.Lark(grammar)
tree = parser.parse(cfg)
print(tree.pretty())
The output should look like this:
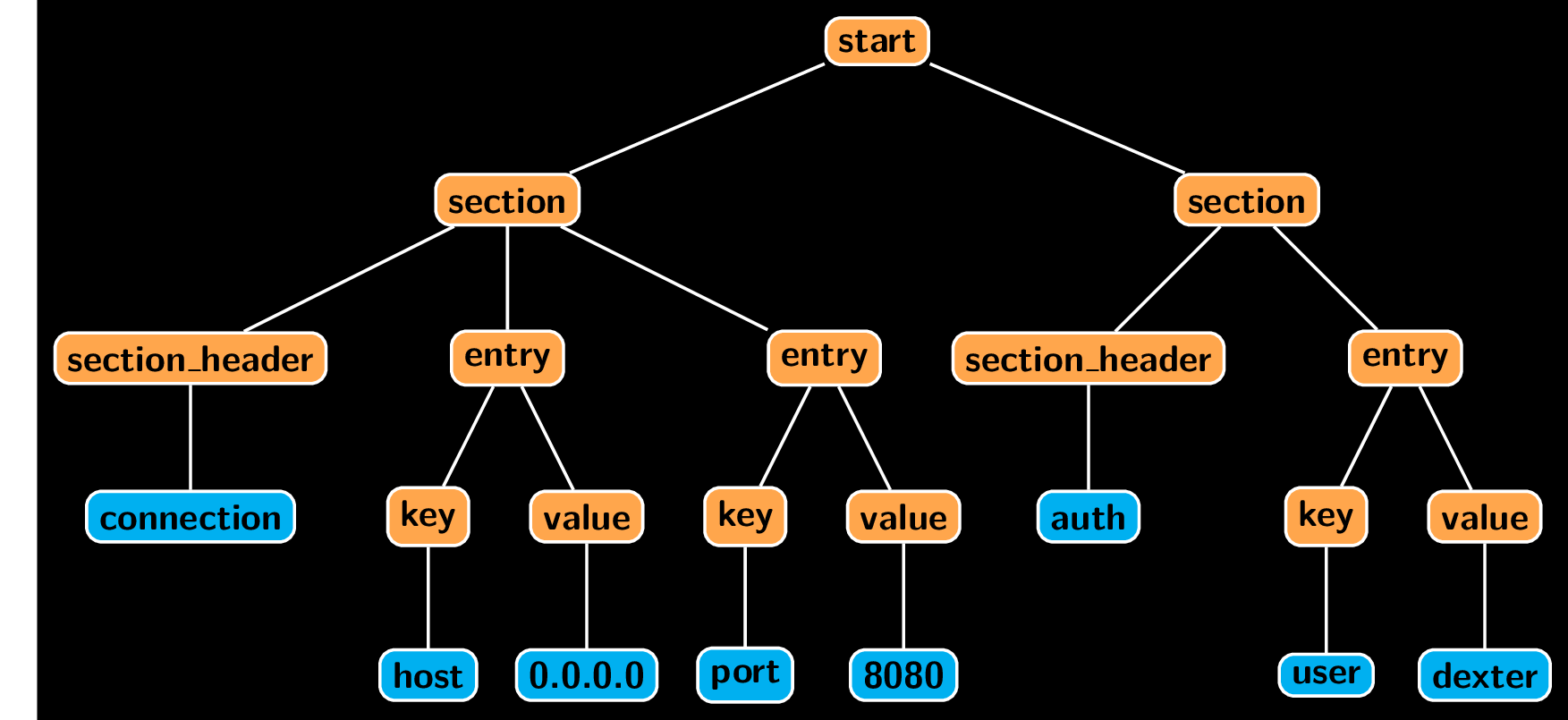
start
section
section_header connection
entry
key host
value 0.0.0.0
entry
key port
value 8080
section
section_header auth
entry
key user
value dexter
It seems that parser got everything right and returned a correct parse tree structure. How do we use it? Let’s first discuss how this tree is stored. The tree variable and all of its subtrees are instances of lark.Tree class. Every path along the tree ends with a terminal symbol, and those are instances of lark.Token class. The Token class is a subclass of str, making it easy to access its content. Each token also stores a name of the terminal it represents. Here is how the tree looks like with the emphasis on the distinction between nonterminal symbols (orange) and terminal ones (blue).
Every tree contains a children attribute, which holds a list of its descendants (either subtrees or tokens). It also exposes some useful methods for iterating over subtrees, finding elements satisfying some predicate etc. I won’t go into details because in the next section we will see an even nicer method of processing trees. Just as an example, here is how you would manually display information from our config file.
# Iterate over all matches in tree corresponding to section symbol.
for i, section in enumerate(tree.find_data('section'), 1):
# Find first (and only) section_header subtree and extract its NAME.
section_name = next(section.find_data('section_header')).children[0]
print(f'Section {i}: {section_name}')
# Iterate over every entry in current section.
for entry in section.find_data('entry'):
# Grab key subtree and extract its leaf only terminal, do the same
# for value subtree.
key = entry.children[0].children[0]
value = entry.children[1].children[0]
print(f' {key}={value}')
Transforming parse tree into something meaningful
Manually processing a parse tree is a bit tedious. Lark offers a nice alternative that allows us to traverse tree bottom up, reducing items as we go. In order to do so, we need to subclass lark.Transformer and implement methods for reducing nonterminal symbols. The methods should be named like the symbol they transform, i.e. if you want to implement a method that transforms section_header you should name it just like that - section_header. Each of such methods should take a single argument matches that will contain all the children of the node being transformed.
It is important to remember that Transformer works bottom up, i.e. it first transforms the items that are closer to the leaves of the parse tree. Therefore at every stage, you can safely assume that the matches already contains transformed children. Having that in mind we could implement our transformer like this.
class CFGTransformer(lark.Transformer):
def key(self, matches):
# Keys can have only one, terminal child. We just convert it
# to string, which strips additional information stored in
# the token.
return str(matches[0])
def value(self, matches):
# Same as with key
return str(matches[0])
def section_header(self, matches):
# And again, just extract string.
return str(matches[0])
def entry(self, matches):
# Entries are transformed into tuples (key, value)
return (matches[0], matches[1])
def section(self, matches):
# Sections are transformed into tuple (name, dictionary of entries).
it_matches = iter(matches)
name = next(it_matches)
data = {entry[0]: entry[1] for entry in it_matches}
return (name, data)
def start(self, matches):
# Start symbol merges data from all sections into larger dict
# keyed with section names.
return {name: data for name, data in matches}
Note that in the entry method we don’t convert matches to str, as this is already taken care of by key and value methods. Also, in the start method we assumed that matches already is a list of tuples of the form (name, data) where name is a string and data is a dictionary - this is because we know that by the time start executes all of its children (in this case sections) have already been transformed.
To transform our parse tree we need to create an instance of the CFGTransformer class and pass tree to its transform method.
transformer = CFGTransformer()
print(transformer.transform(tree))
We should get a dictionary with the following contents:
{
'connection': {
'host': '0.0.0.0',
'port': '8080'
},
'auth': {
'user': 'dexter'
}
}
If this wasn’t elegant enough, in the next section we will see how to make our transformer even better.
Using v_args to make transformer more elegant
In the previous example, there is a single inconvenience. Even when we know that our symbol will always have a single match we still have to refer to it as matches[0]. The same goes about symbols with any constant number of matches. We can leverage lark.v_args decorator to fix this. The idea is simple: instead of unpacking matches by yourself have lark unpack it for you. In the simplest case, you decorate your transformer (passing inline=True to v_args) and all of the matches will be unpacked into *args. Let’s see how this works.
@lark.v_args(inline=True)
class CFGTransformer(lark.Transformer):
def key(self, key_token):
return str(key_token)
def value(self, value_token):
return str(value_token)
def section_header(self, section_name):
return str(section_name)
def entry(self, key, value):
return (key, value)
def section(self, name, *entries):
data = {entry[0]: entry[1] for entry in entries}
return (name, data)
def start(self, *sections):
return {name: data for name, data in sections}
Neat, isn’t it? The transformer above should yield precisely the same outputs as its first version.
Final thoughts
As we can see, parsing context-free grammars using lark is really a straightforward process. Note that as there is no point in repeating lark’s documentation, we only discussed some selected subset of its features. In particular, we haven’t touched topics such as:
- tree shaping,
- using other parsers (by default
larkuses Earley parser but has other parsers implemented as well), - visitors,
- handling ambiguity in grammars.
Last but not least, if you want to take a look at some more complex, practical example check out Kristal. It is still in an early development stage, but we already implemented parser for Crystallographic Information Files mentioned in the introduction based on Lark.